OpenAIのAPIを使って、ChatGPTのようにテキスト応答と画像生成を自動で判断して処理するSlackBOTを作る
はじめに
この記事では、自然言語処理を行うGPTモデルと、画像を生成するDALL-Eモデルの2つを組み合わせて、ChatGPTのように、会話内容から判断して、テキスト応答か画像生成するプログラムについて紹介します。
プログラムの概要
このプログラムは、Slack上でのユーザーからのメッセージの内容に応じて、テキスト応答か画像生成を行います。具体的には、ユーザーからのメッセージが画像生成を要求しているかどうかを GPTモデルが判断し、画像生成を要求していると判断した場合はDALL-Eがプロンプトに基づいて画像を生成し、それ以外の場合はGPTモデルで処理します。
プログラムの開発には、Python言語、OpenAIのAPI(GPT-4とDALL-Eモデル)、そしてSlackのAPIを使用します。

ソースコード
import os
import openai
import datetime
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
# 環境変数の設定
SLACK_BOT_TOKEN = os.environ.get("SLACK_BOT_TOKEN")
SLACK_APP_TOKEN = os.environ["SLACK_APP_TOKEN"]
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
# OpenAI APIキーの設定
openai.api_key = OPENAI_API_KEY
# Slackアプリの初期化
app = App(token=SLACK_BOT_TOKEN)
# 対話履歴とモデルの設定
channel_conversation_history = {}
last_interaction_time = {}
model = "gpt-4-1106-preview" # デフォルトモデルを設定
# GPTによる会話解析と画像生成の推奨
def analyze_and_recommend_image(message):
try:
response = openai.ChatCompletion.create(
model="gpt-4-1106-preview", # 分析用のモデルを指定
messages=[
{"role": "system", "content": "Analyze the message provided. If the message explicitly requests the creation of a photograph, drawing, illustration, or any form of visual artwork, respond with 'Yes'.This includes requests for specific scenes, objects, concepts, or designs to be visualized. However, if the message does not explicitly ask for an image or is seeking information, explanations, or any non-visual content, respond with 'No'. This applies to general questions, requests for written content, or any query where a visual representation is not directly requested."},
{"role": "user", "content": message}
]
)
return "Yes" in response['choices'][0]['message']['content']
except Exception as e:
print(f"Error in analyze_and_recommend_image: {e}")
return False
# DALL-E APIを呼び出す関数
def generate_dalle_image(prompt):
try:
response = openai.Image.create(
model="dall-e-3",
prompt=prompt,
n=1,
size="1024x1024"
)
image_url = response['data'][0]['url']
return image_url
except openai.error.InvalidRequestError as e:
return "error"
# Slackに画像を投稿する関数
def post_image_to_slack(channel_id, image_url, ts):
try:
if image_url == "error":
app.client.chat_update(
channel=channel_id,
ts=ts,
text="画像を生成できませんでした。"
)
else:
app.client.chat_update(
channel=channel_id,
ts=ts,
text="",
blocks=[
{
"type": "image",
"title": {
"type": "plain_text",
"text": "Generated Image"
},
"image_url": image_url,
"alt_text": "Generated Image"
}
]
)
except Exception as e:
logger.error(f"Error posting image to Slack: {e}")
# Slackイベントハンドラ
@app.event("message")
def handle_message(body, logger):
global channel_conversation_history
global last_interaction_time
user_id = body["event"]["user"]
channel_id = body["event"]["channel"]
message = body["event"]["text"]
initial_message_response = app.client.chat_postMessage(
channel=channel_id,
text="..."
)
ts = initial_message_response['ts']
if analyze_and_recommend_image(message):
image_url = generate_dalle_image(message)
post_image_to_slack(channel_id, image_url, ts)
else:
if channel_id not in channel_conversation_history:
channel_conversation_history[channel_id] = []
if channel_id not in last_interaction_time or (datetime.datetime.now() - last_interaction_time[channel_id]).seconds > 3600:
channel_conversation_history[channel_id] = []
last_interaction_time[channel_id] = datetime.datetime.now()
gpt_response = get_gpt_response(channel_conversation_history[channel_id], message, model)
try:
app.client.chat_update(
channel=channel_id,
ts=ts,
if __name__ == "__main__":
handler = SocketModeHandler(app, SLACK_APP_TOKEN)
handler.start()ソースコードの解説
ソースコードは主に、Slackイベントの処理、メッセージの分析、GPTモデルによるテキスト応答の生成、DALL-Eによる画像生成の4つの主要部分で構成されています。
1. Slackイベントの処理
Slackのイベントハンドラはユーザーのメッセージを受け取り、後続の処理を開始します。以下のコードはメッセージイベントを受け取るためのハンドラの例です。
@app.event("message")
def handle_message(body, logger):
user_id = body["event"]["user"]
channel_id = body["event"]["channel"]
message = body["event"]["text"]
initial_message_response = app.client.chat_postMessage(
channel=channel_id,
text="..."
)
ts = initial_message_response['ts']
if analyze_and_recommend_image(message):
# 画像生成の処理
else:
# テキスト応答の生成
この関数では、Slackからメッセージを受け取り、その内容に基づいて画像生成を行うか、またはテキスト応答を生成するかを決定します。
2. メッセージ分析
メッセージ分析では、GPTモデルがメッセージ内容を解析し、画像生成が必要かどうかを判断します。以下の関数がその例です。
def analyze_and_recommend_image(message):
try:
response = openai.ChatCompletion.create(
model="gpt-4-1106-preview",
messages=[
{"role": "system", "content": "Analyze the message provided. If the message explicitly requests the creation of a photograph, drawing, illustration, or any form of visual artwork, respond with 'Yes'.This includes requests for specific scenes, objects, concepts, or designs to be visualized. However, if the message does not explicitly ask for an image or is seeking information, explanations, or any non-visual content, respond with 'No'. This applies to general questions, requests for written content, or any query where a visual representation is not directly requested."},
{"role": "user", "content": message}
]
)
return "Yes" in response['choices'][0]['message']['content']
except Exception as e:
print(f"Error in analyze_and_recommend_image: {e}")
return False分析の精度を向上させるため細かく指示をしています。トークン数の節約のため英語にしています。
「与えられたメッセージを分析してください。もしメッセージが写真、絵、イラスト、または視覚的なアートワークの作成を明示的に要求している場合は「Yes」と回答してください。これには特定のシーン、物体、概念、または視覚化されるべきデザインのリクエストが含まれます。しかし、もしメッセージが画像を明示的に求めていない、または情報、説明、または非視覚的なコンテンツを求めている場合は「No」と回答してください。これは一般的な質問、文章コンテンツのリクエスト、または視覚的な表現が直接要求されていない任意の問い合わせに適用されます」
3. テキスト応答の生成
テキスト応答の生成では、GPTモデルが適切な応答を作成します。この関数は、会話履歴と新しいメッセージを基に、GPTモデルを使って適切なテキスト応答を生成します。
def get_gpt_response(conversation_history, message, model_name):
conversation_history.append({"role": "user", "content": message})
# トークン数のチェックと会話履歴の調整
response = openai.ChatCompletion.create(
model=model_name,
messages=[{"role": "system", "content": "You are a helpful assistant."}] + conversation_history
)
assistant_message = response.choices[0]['message']['content'].strip()
conversation_history.append({"role": "assistant", "content": assistant_message})
return assistant_message
4. 画像生成
画像生成では、DALL-Eが与えられたプロンプトに基づいて画像を生成します。
def generate_dalle_image(prompt):
try:
response = openai.Image.create(
model="dall-e-3",
prompt=prompt,
n=1,
size="1024x1024"
)
image_url = response['data'][0]['url']
return image_url
except openai.error.InvalidRequestError as e:
return "error"
実装例
実装のデモンストレーションとして、Slack上での実際の対話スクリーンショットや生成された画像の例を示します。
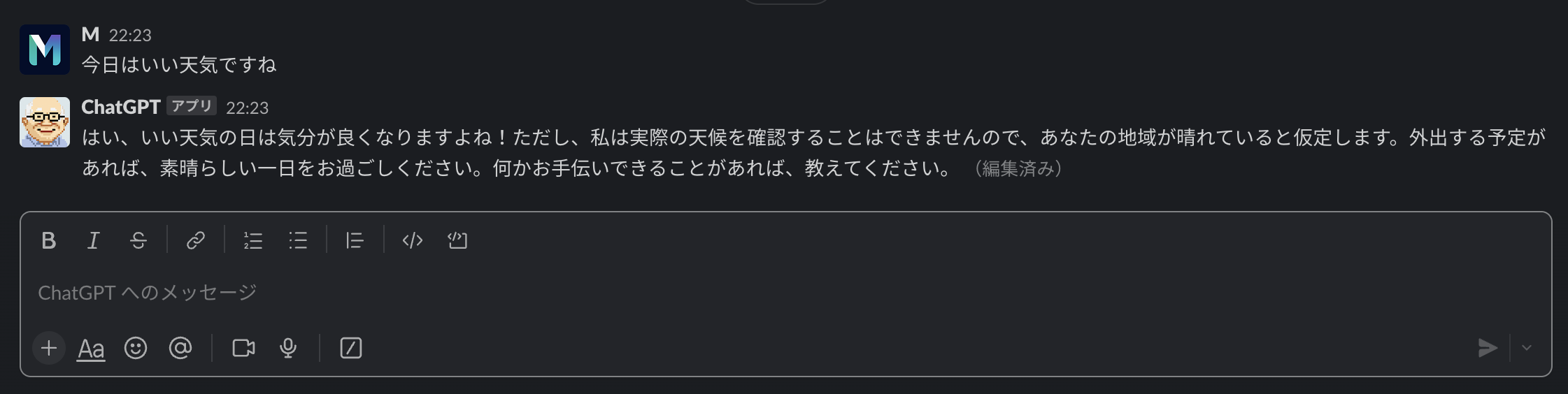
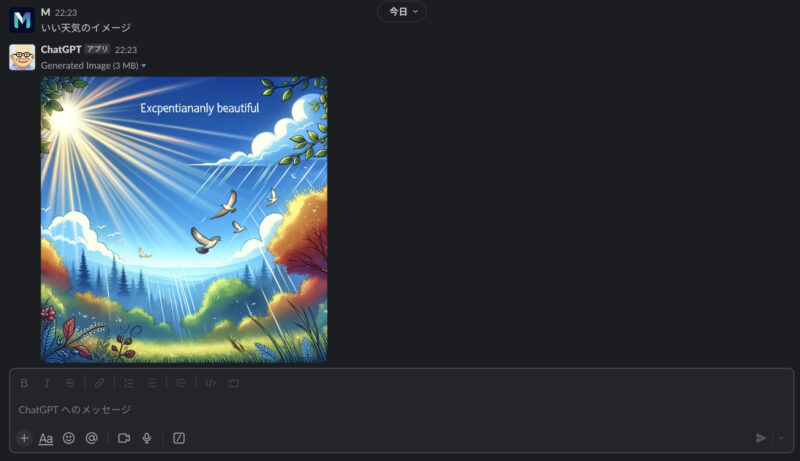
結論
今回は、ユーザーのメッセージを最初に分析することで、特定のタグや文言に縛られずにテキスト応答と画像生成の両方を実現することができました。今後は、画像生成か判断する以外にも、過去の会話履歴を参照するとか、インターネットの情報を検索するとかその辺りの分岐も一緒に組み込むと面白いかなと思っています。

関連記事
 " data-srcset="'https://ubun2m.com/wp-content/uploads/2025/06/ChatGPT-Image-2025年6月29日-18_24_30.jpg 150w, https://ubun2m.com/wp-content/uploads/2025/06/ChatGPT-Image-2025年6月29日-18_24_30.jpg 720w" sizes="(max-width: 360px) 100vw, 360px"/>
" data-srcset="'https://ubun2m.com/wp-content/uploads/2025/06/ChatGPT-Image-2025年6月29日-18_24_30.jpg 150w, https://ubun2m.com/wp-content/uploads/2025/06/ChatGPT-Image-2025年6月29日-18_24_30.jpg 720w" sizes="(max-width: 360px) 100vw, 360px"/>
") " data-srcset="'https://ubun2m.com/wp-content/uploads/2023/02/img-XipYIXQI2OqOiFniK9mgDkan.png 150w, https://ubun2m.com/wp-content/uploads/2023/02/img-XipYIXQI2OqOiFniK9mgDkan.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>
" data-srcset="'https://ubun2m.com/wp-content/uploads/2023/02/img-XipYIXQI2OqOiFniK9mgDkan.png 150w, https://ubun2m.com/wp-content/uploads/2023/02/img-XipYIXQI2OqOiFniK9mgDkan.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>
 " data-srcset="'https://ubun2m.com/wp-content/uploads/2025/02/jidouimo-400x400.webp 150w, https://ubun2m.com/wp-content/uploads/2025/02/jidouimo-400x400.webp 720w" sizes="(max-width: 360px) 100vw, 360px"/>
" data-srcset="'https://ubun2m.com/wp-content/uploads/2025/02/jidouimo-400x400.webp 150w, https://ubun2m.com/wp-content/uploads/2025/02/jidouimo-400x400.webp 720w" sizes="(max-width: 360px) 100vw, 360px"/>