形態素解析を使ってハリー・ポッターをフランス語で楽しく読みたい【Python】
はじめに
筆者の語学力ではハリー・ポッターのフランス語版は読みづらい。その理由は、フランス語の語彙力が少ないことなので、もし使われている単語を効率的に覚えることが出来れば、読みやすくなるのではないかと思った。原書の英語版はガイドブックが出版されているので良いが、フランス語版はない。そこで今回は、形態素解析を利用して使用頻度が高い順に単語を抽出することにした。これにより、ハリー・ポッターのフランス語版を読む際に役立つ単語を覚えることができ、読みやすくなり、より楽しめるかもしれない。

形態素解析とは何か
形態素解析(けいたいそかいせき、Morphological analysis)は、自然言語処理において、文章を単位とする形態素(Morpheme)に分解することを指す。
形態素とは、言語学において文章を構成する最小の単位であり、言葉や単語を解析し、基本形や品詞などの情報を取り出すために使用される。形態素解析は、機械学習や人工知能の研究にも用いられる。
spaCyを使った形態素解析
今回の形態素解析にはspaCyを利用する。sdpaCyは、Pythonで書かれた自然言語処理のライブラリである。形態素解析、文章のトピック分類などのタスクを実行するためのAPIを提供している。spaCyは高い処理速度と精度、そして使いやすいのが特徴である。多言語に対応しているため、英語、ドイツ語、フランス語など多くの言語を扱うことができる。
なお、SpaCyのフランス語モデルで使用される品詞タグには以下の種類がある。
- ADJ : adjective (形容詞)
- ADP : adposition (前置詞)
- ADV : adverb (副詞)
- AUX : auxiliary (助動詞)
- CCONJ : coordinating conjunction (語節連接)
- DET : determiner (限定詞)
- INTJ : interjection (感動詞)
- NOUN : noun (名詞)
- NUM : numeral (数詞)
- PART : particle (助詞)
- PRON : pronoun (代名詞)
- PROPN : proper noun (固有名詞)
- PUNCT : punctuation (句読点)
- SCONJ : subordinating conjunction (接続詞)
- SYM : symbol (記号)
- VERB : verb (動詞)
- X : other (その他)
作成したソースコード
このソースコードは、フランス語のテキストファイルから使用頻度が高い順に単語を抽出するためのPythonのプログラムである。
まず最初に、spaCyという自然言語処理のライブラリをインポートし、フランス語のモデルを読み込む。
main関数では、テキストファイルを開き、その内容を変数に読み込む。その後、get_lemma_pos_counts関数を使用して、lemma(基本形), pos(品詞), count(出現回数)を取得し、書き込み用のcsvファイルに書き込む。
get_lemma_pos_counts関数では、引数として与えられたテキストから、単語のlemma、pos、その単語の出現回数を取得する。各行についてspaCyを使って処理をしている。そして、lemma, pos, countのリストを作成し、countの多い順にソートしてmain関数にデータを返す。
このソースコードを実行することで、フランス語のテキストファイルから使用頻度が高い順に単語を抽出し、それらをcsvファイルに書き出すことができる。
# coding: utf-8
import spacy
from collections import defaultdict
import csv
# spaCyを使用して、frenchのモデルを読み込む
nlp = spacy.load("fr_core_news_sm")
# 処理したテキストからlemma, pos, countを取得する関数
def get_lemma_pos_counts(lines):
# lemma, posごとにカウントするための辞書を作成
lemma_pos_counts = defaultdict(lambda: defaultdict(int))
# テキストの中の各行について処理
for line in lines:
# spaCyを使用して、行を処理
doc = nlp(line)
# 処理済みテキストの中の各トークンについて
for token in doc:
# トークンのposがPUNCTやSPACEでない場合
if token.pos_ not in ["PUNCT", "SPACE"]:
# 現在のlemma, posのカウントを更新
lemma_pos_counts[token.lemma_][token.pos_] += 1
# lemma, pos, countのリストを作成
lemma_pos_counts_list = [(lemma, pos, count) for lemma, pos_counts in lemma_pos_counts.items() for pos, count in pos_counts.items()]
# countの多い順にソート
lemma_pos_counts_list.sort(key=lambda x: x[2], reverse=True)
return lemma_pos_counts_list
def main():
# テキストファイルを開く
with open('textfile.txt', 'r') as file:
# ファイルの内容を変数に読み込む
lines = file.readlines()
conversation_lines = []
# 各行について処理
for line in lines:
conversation_lines.append(line)
# 関数を使用して、lemma, pos, countを取得
conversation_lemma_pos_counts = get_lemma_pos_counts(conversation_lines)
# 書き込み用のファイルを開く
with open("lemma_pos_counts.csv", "w") as f:
# CSVライターオブジェクトを作成
writer = csv.writer(f)
# ヘッダーを書き込む
writer.writerow(["lemma", "pos", "count"])
# 各行を書き込む
for row in conversation_lemma_pos_counts:
lemma, pos, count = row
writer.writerow([lemma, pos, count])
if __name__ == "__main__":
main()ハリー・ポッターのテキストファイルを用いて実際に形態素解析を行った結果
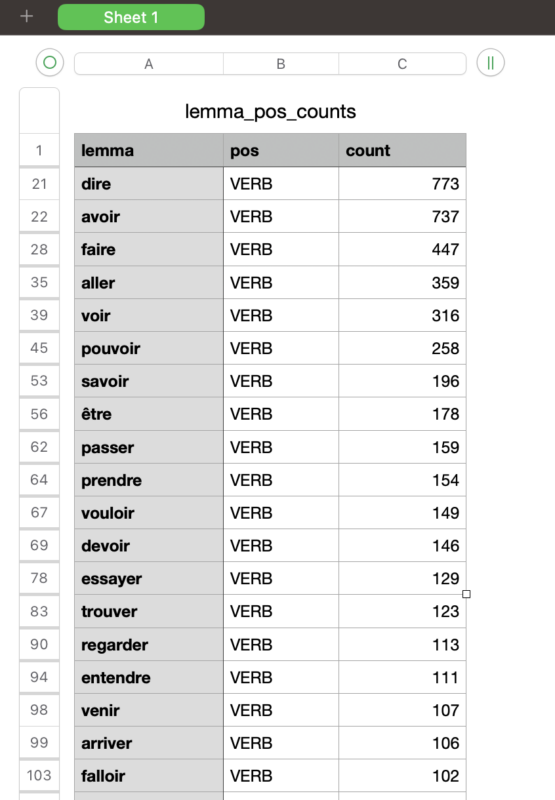
実際にハリー・ポッター1巻「Rowling, J.K.. Harry Potter à L’école des Sorciers (French Edition)」のテキストファイルを用いて形態素解析を行った結果、最も頻出した単語は「être」、「avoir」、「et」、「de」、「le」などであった。これらは、フランス語の文章でよく使用される助動詞や前置詞などの基本的な単語である。

そのままでは、代名詞、前置詞、限定詞などの単語ばかり上位に来るため、csvデータをさらにフィルタリングした。
動詞だけを抽出した結果、最も頻出した動詞は「dire」、「faire」、「avoir」、「aller」、「voir」などである。これらは、フランス語の文章でよく使用される動詞である。
これらの結果から、問題なく動作していることが確認できる。
おわりに
形態素解析の結果から得られた頻出単語のリストには、すでに知っている単語も含まれている。そのため、頻出単語のうち、まだ知らない単語を見つけるための作業が必要になる。知らない単語をチェックする方法は別の記事で紹介している。これにより、特定の本を読む上で役立つ単語を素早く覚えることができ、より楽しむことができるだろう。
英語やフランス語など、読みたい本のテキストデータが用意できれば、同じ方法で形態素解析を行うことができるので、興味がある方はぜひ試して欲しい。

関連記事
 " data-srcset="'https://ubun2m.com/wp-content/uploads/2024/01/Screenshot-2024-01-14-at-15.52.10.png 150w, https://ubun2m.com/wp-content/uploads/2024/01/Screenshot-2024-01-14-at-15.52.10.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>
" data-srcset="'https://ubun2m.com/wp-content/uploads/2024/01/Screenshot-2024-01-14-at-15.52.10.png 150w, https://ubun2m.com/wp-content/uploads/2024/01/Screenshot-2024-01-14-at-15.52.10.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>
 " data-srcset="'https://ubun2m.com/wp-content/uploads/2023/01/img-f2PDVGweByEHBn6rMLTXvnPP-e1674950697891.png 150w, https://ubun2m.com/wp-content/uploads/2023/01/img-f2PDVGweByEHBn6rMLTXvnPP-e1674950697891.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>
" data-srcset="'https://ubun2m.com/wp-content/uploads/2023/01/img-f2PDVGweByEHBn6rMLTXvnPP-e1674950697891.png 150w, https://ubun2m.com/wp-content/uploads/2023/01/img-f2PDVGweByEHBn6rMLTXvnPP-e1674950697891.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>
 " data-srcset="'https://ubun2m.com/wp-content/uploads/2023/01/img-9zlh2mu7GEDlQEHgXG2NJNVf.png 150w, https://ubun2m.com/wp-content/uploads/2023/01/img-9zlh2mu7GEDlQEHgXG2NJNVf.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>
" data-srcset="'https://ubun2m.com/wp-content/uploads/2023/01/img-9zlh2mu7GEDlQEHgXG2NJNVf.png 150w, https://ubun2m.com/wp-content/uploads/2023/01/img-9zlh2mu7GEDlQEHgXG2NJNVf.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>