国立国会図書館サーチAPIを利用したKindleの蔵書整理
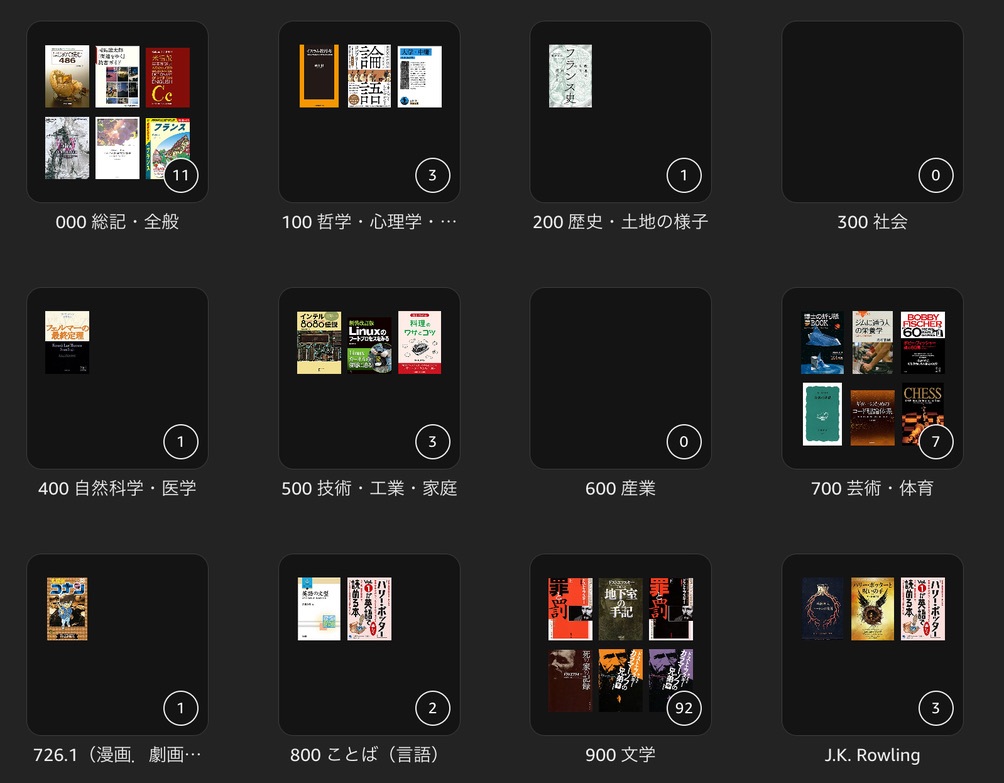
日本十進分類法(NDC)でKindleのコレクションを整理するための補助ツールを作った。python3で動作確認。
import xml.etree.ElementTree
import urllib.parse
import requests
import csv
import re
namespaces = {'openSearch':'http://a9.com/-/spec/opensearchrss/1.0/',
'dc':'http://purl.org/dc/elements/1.1/',
'rdf':'http://www.w3.org/1999/02/22-rdf-syntax-ns#'}
def searchNDC(title,author):
# 検索に不都合な要素を削除
title = re.sub('【.+?】', ' ', title)
title = re.sub('(.+?)', ' ', title)
title = re.sub('〈.+?〉', ' ', title)
title = re.sub('\(.+?\)', ' ', title)
title = title.replace(' ', ' ')
author = author.replace(':', ' ')
url = "https://iss.ndl.go.jp/api/opensearch?cnt=5&title=" + urllib.parse.quote(title) + "&creator=" + urllib.parse.quote(author) + "&dpid=iss-ndl-opac"
res = requests.get(url)
root = xml.etree.ElementTree.fromstring(res.text)
totalResults = root.findall('.//openSearch:totalResults',namespaces)
for title_element in totalResults:
print("Results=" + title_element.text + " Search=" + title + " " + author)
for item in root.iter('item'):
ary=[]
for name in item.iter('title'):
ary.append(name.text)
for name in item.iter('author'):
ary.append(name.text)
title_elements = item.findall('.//dc:subject',namespaces)
for title_element in title_elements:
ary.append(title_element.text)
print(ary)
csv_file = open("./download.csv", "r", encoding="utf_8", errors="", newline="" )
#csv 読み込み
f = csv.reader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True)
# Main
for i,row in enumerate(f):
print("Row:" + str(i))
searchNDC(row[1],row[2])動作確認
使用するためには、別途Kindleの蔵書一覧を抽出したCSVファイルが必要となる。抽出方法については、以前の記事で紹介している。

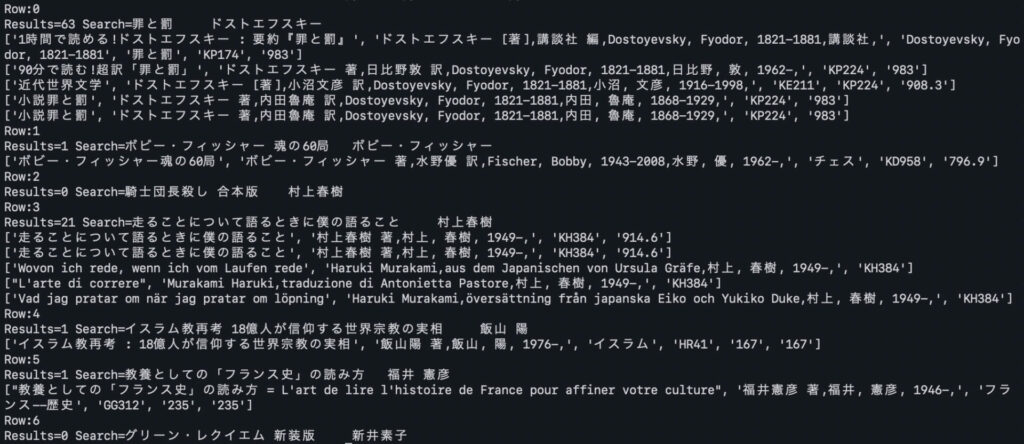
タイトルに「合本版」や「新装版」などと入っている本については検索結果が0となっている。これらを取り除く処理を入れると検索できるのだが、バリエーションが多いので、とりあえず必要と思われる処理だけ入れた。
問題点
・検索結果が複数ある場合、どのNDCを使うか個別に確認する必要がある。
・Kindleのコレクションに追加する作業は手作業。(かなり面倒くさい)
→ APIはなさそうなので、画像認識を利用して自動化する予定。
参考HP
東京都立図書館 - NDCって何?
https://www.library.metro.tokyo.lg.jp/support_school/research/for_study/report_guide/tool/ndc/
国立国会図書館サーチ - APIのご利用について
https://iss.ndl.go.jp/information/api/
国立国会図書館サーチ - インタフェース仕様書(第2.1版)
https://iss.ndl.go.jp/information/wp-content/uploads/2021/03/ndlsearch_api_20210329_jp.pdf

関連記事
 " data-srcset="'https://ubun2m.com/wp-content/uploads/2022/02/Untitled_Artwork-4-400x400.png 150w, https://ubun2m.com/wp-content/uploads/2022/02/Untitled_Artwork-4-400x400.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>
" data-srcset="'https://ubun2m.com/wp-content/uploads/2022/02/Untitled_Artwork-4-400x400.png 150w, https://ubun2m.com/wp-content/uploads/2022/02/Untitled_Artwork-4-400x400.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>
 " data-srcset="'https://ubun2m.com/wp-content/uploads/2022/12/output-2-1-400x300.jpg 150w, https://ubun2m.com/wp-content/uploads/2022/12/output-2-1-400x300.jpg 720w" sizes="(max-width: 360px) 100vw, 360px"/>
" data-srcset="'https://ubun2m.com/wp-content/uploads/2022/12/output-2-1-400x300.jpg 150w, https://ubun2m.com/wp-content/uploads/2022/12/output-2-1-400x300.jpg 720w" sizes="(max-width: 360px) 100vw, 360px"/>
 " data-srcset="'https://ubun2m.com/wp-content/uploads/2023/01/uranai_suisyou-1.png 150w, https://ubun2m.com/wp-content/uploads/2023/01/uranai_suisyou-1.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>
" data-srcset="'https://ubun2m.com/wp-content/uploads/2023/01/uranai_suisyou-1.png 150w, https://ubun2m.com/wp-content/uploads/2023/01/uranai_suisyou-1.png 720w" sizes="(max-width: 360px) 100vw, 360px"/>